Resilient Distributed Datasets
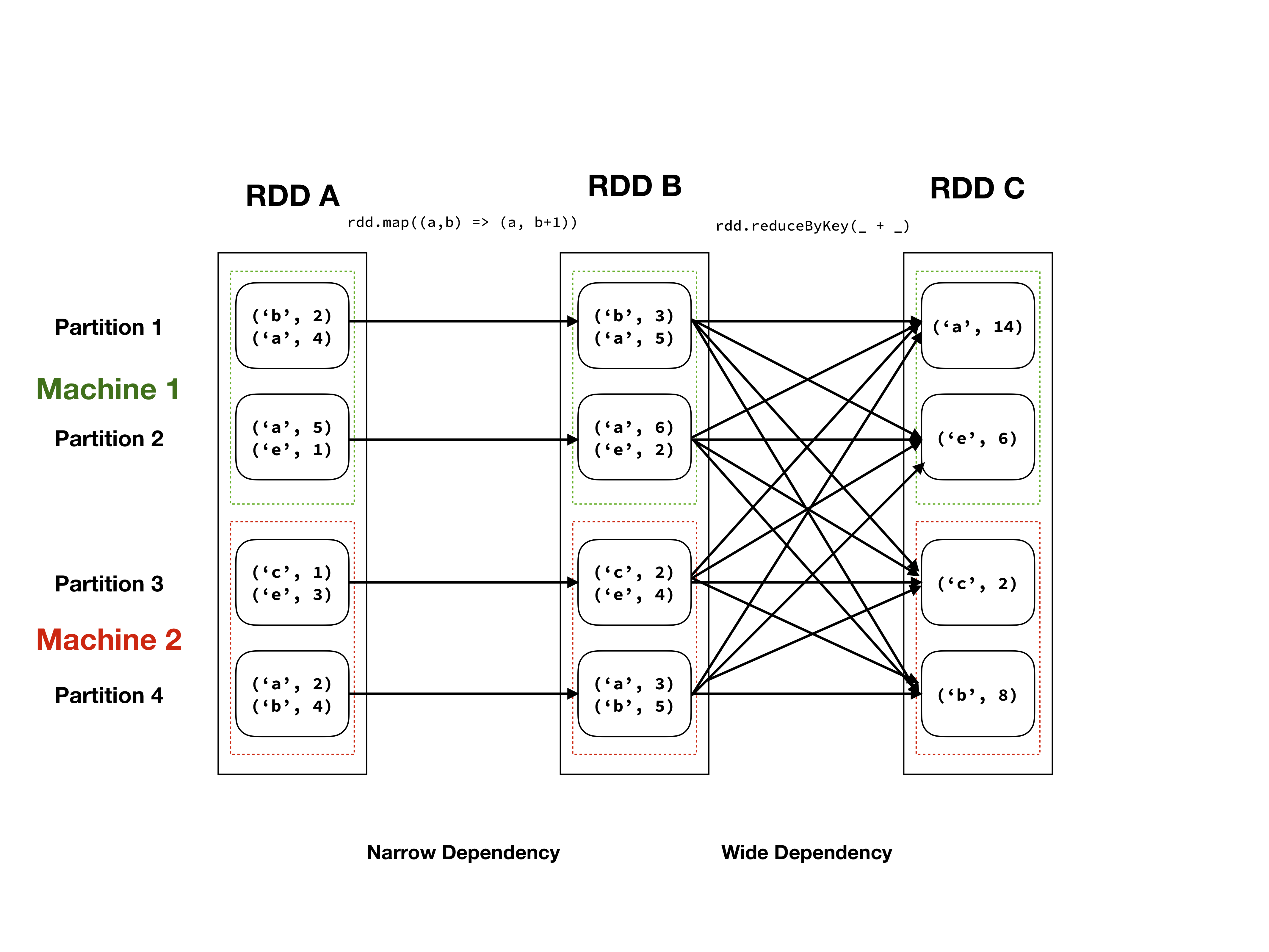
Illustration of RDD abstraction of an RDD with a tuple of characters and integers as elements.
RDDs are the original data abstraction used in Spark. Conceptually one can think of these as a large, unordered list of Java/Scala/Python objects, let's call these objects elements. This list of elements is divided in partitions (which may still contain multiple elements), which can reside on different machines. One can operate on these elements with a number of operations, which can be subdivided in wide and narrow dependencies, see the table below. An illustration of the RDD abstraction can be seen in the figure above.
RDDs are immutable, which means that the elements cannot be altered, without creating a new RDD. Furthermore, the application of transformations (wide or narrow) is lazy evaluation, meaning that the actual computation will be delayed until results are requested (an action in Spark terminology). When applying transformations, these will form a directed acyclic graph (DAG), that instructs workers what operations to perform, on which elements to find a specific result. This can be seen in the figure above as the arrows between elements.
| Narrow Dependency | Wide Dependency |
|---|---|
map | coGroup |
mapValues | flatMap |
flatMap | groupByKey |
filter | reduceByKey |
mapPartitions | combineByKey |
mapPartitionsWithIndex | distinct |
join with sorted keys | join |
intersection | |
repartition | |
coalesce | |
sort |
List of wide and narrow dependencies for (pair) RDD operations
Now that you have an idea of what the abstraction is about, let's demonstrate some example code with the Spark shell.
If you want to paste pieces of code into the spark shell from this guide, it
might be useful to copy from the github version, and use the :paste command in
the spark shell to paste the code. Hit ctrl+D to stop pasting.
We can start the shell using Docker:
docker run -it --rm -v "`pwd`":/io spark-shell
We should now get the following output:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/spark/jars/spark-unsafe_2.12-3.1.2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2021-09-06 08:36:27,947 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://a4a64e0fea2c:4040
Spark context available as 'sc' (master = local[*], app id = local-1630917390997).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
When opening a Spark Shell, by default, you get two objects.
- A
SparkSessionnamedspark. - A
SparkContextnamedsc.
These objects contains the configuration of your session, i.e. whether you are running in local or cluster mode, the name of your application, the logging level etc.
We can get some (sometimes slightly arcane) information about Scala objects that exist in the scope of the shell, e.g.:
scala> spark
res0: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@747e0a31
Now, let's first create some sample data that we can demonstrate the RDD API around. Here we create an infinite list of repeating characters from 'a' tot 'z'.
scala> val charsOnce = ('a' to 'z').toStream
charsOnce: scala.collection.immutable.Stream[Char] = Stream(a, ?)
scala> val chars: Stream[Char] = charsOnce #::: chars
chars: Stream[Char] = Stream(a, ?)
Now we build a collection with the first 200000 integers, zipped with the character stream. We display the first five results.
scala> val rdd = sc.parallelize(chars.zip(1 to 200000), numSlices=20)
rdd: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:26
scala> rdd.take(5)
res2: Array[(Char, Int)] = Array((a,1), (b,2), (c,3), (d,4), (e,5))
Let's dissect what just happened. We created a Scala object that is a list of
tuples of Chars and Ints in the statement (chars).zip(1 to 200000). With
sc.parallelize we are transforming a Scala sequence into an RDD. This allows
us to enter Spark's programming model. With the optional parameter numSlices
we indicate in how many partitions we want to subdivide the sequence.
Let's apply some (lazily evaluated) transformations to this RDD.
scala> val mappedRDD = rdd.map({case (chr, num) => (chr, num+1)})
mappedRDD: org.apache.spark.rdd.RDD[(Char, Int)] = MapPartitionsRDD[1] at map at <console>:25
We apply a map to the RDD, applying a function to all the elements in the
RDD. The function we apply pattern matches over the elements as being a tuple
of (Char, Int), and add one to the integer. Scala's syntax can be a bit
foreign, so if this is confusing, spend some time looking at tutorials and
messing around in the Scala interpreter.
You might have noticed that the transformation completed awfully fast. This is Spark's lazy evaluation in action. No computation will be performed until an action is applied.
scala> val reducedRDD = rdd.reduceByKey(_ + _)
reducedRDD: org.apache.spark.rdd.RDD[(Char, Int)] = ShuffledRDD[2] at reduceByKey at <console>:25
Now we apply a reduceByKey operation, grouping all of the identical keys together and
merging the results with the specified function, in this case the + operator.
Now we will perform an action, which will trigger the computation of the transformations on the data. We will use the collect action, which means to gather all the results to the master, going out of the Spark programming model, back to a Scala sequence. How many elements do you expect there to be in this sequence after the previous transformations?
scala> reducedRDD.collect
res3: Array[(Char, Int)] = Array((d,769300000), (x,769253844), (e,769307693),
(y,769261536), (z,769269228), (f,769315386), (g,769323079), (h,769330772),
(i,769138464), (j,769146156), (k,769153848), (l,769161540), (m,769169232),
(n,769176924), (o,769184616), (p,769192308), (q,769200000), (r,769207692),
(s,769215384), (t,769223076), (a,769276921), (u,769230768), (b,769284614),
(v,769238460), (w,769246152), (c,769292307))
Typically, we don't build the data first, but we actually load it from a
database or file system. Say we have some data in (multiple) files in a
specific format. As an example consider sensordata.csv (in the example
folder). We can load it as follows:
// sc.textFile can take multiple files as argument!
scala> val raw_data = sc.textFile("sensordata.csv")
raw_data: org.apache.spark.rdd.RDD[String] = sensordata.csv MapPartitionsRDD[1] at textFile at <console>:24
And observe some of its contents:
scala> raw_data.take(10).foreach(println)
COHUTTA,3/10/14:1:01,10.27,1.73,881,1.56,85,1.94
COHUTTA,3/10/14:1:02,9.67,1.731,882,0.52,87,1.79
COHUTTA,3/10/14:1:03,10.47,1.732,882,1.7,92,0.66
COHUTTA,3/10/14:1:05,9.56,1.734,883,1.35,99,0.68
COHUTTA,3/10/14:1:06,9.74,1.736,884,1.27,92,0.73
COHUTTA,3/10/14:1:08,10.44,1.737,885,1.34,93,1.54
COHUTTA,3/10/14:1:09,9.83,1.738,885,0.06,76,1.44
COHUTTA,3/10/14:1:11,10.49,1.739,886,1.51,81,1.83
COHUTTA,3/10/14:1:12,9.79,1.739,886,1.74,82,1.91
COHUTTA,3/10/14:1:13,10.02,1.739,886,1.24,86,1.79
We can process this data to filter only measurements on 3/10/14:1:01.
scala> val filterRDD = raw_data.map(_.split(",")).filter(x => x(1) == "3/10/14:1:01")
filterRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[11] at filter at <console>:25
And look at the output:
scala> filterRDD.foreach(a => println(a.mkString(" ")))
COHUTTA 3/10/14:1:01 10.27 1.73 881 1.56 85 1.94
LAGNAPPE 3/10/14:1:01 9.59 1.602 777 0.09 88 1.78
NANTAHALLA 3/10/14:1:01 10.47 1.712 778 1.96 76 0.78
CHER 3/10/14:1:01 10.17 1.653 777 1.89 96 1.57
THERMALITO 3/10/14:1:01 10.24 1.75 777 1.25 80 0.89
ANDOUILLE 3/10/14:1:01 10.26 1.048 777 1.88 94 1.66
BUTTE 3/10/14:1:01 10.12 1.379 777 1.58 83 0.67
CARGO 3/10/14:1:01 9.93 1.903 778 0.55 76 1.44
MOJO 3/10/14:1:01 10.47 1.828 967 0.36 77 1.75
BBKING 3/10/14:1:01 10.03 0.839 967 1.17 80 1.28
You might have noticed that this is a bit tedious to work with, as we have to convert everything to Scala objects, and aggregations rely on having a pair RDD, which is fine when we have a single key. For more complex aggregations, this becomes a bit tedious to juggle with.